I finally did something I’ve been meaning to do for a long time: get the final version of the ftape driver to work on a Linux distro that I can use in my data recovery workstations. This is for the purpose of using Linux to dump the contents of QIC-80 and similar tapes, using “floppy tape” drives, i.e. tape drives that connect to the floppy disk controller on the motherboard.
Up until this point, I’ve been using an old version of Ubuntu that has ftape pre-packaged into the kernel. The problem with this is that this version of ftape is not the latest. Development of ftape seemed to continue independently of the version that was included with the kernel. And the “last” version of ftape that is available (version 4.04a, from around July 2000) contains many enhancements over the version that was in the kernel, which seems to be 3.04, specifically compatibility with parallel port tape drives such as the Iomega Ditto 2GB.
This meant that I needed to compile the driver from source. Sounds simple enough; the driver is just a couple of loadable kernel modules. However, I would need to compile it for a version of the kernel that can boot nicely on my workstation. Browsing the source code of the driver, it appears to be intended to be compiled for kernel version 2.4.x. As an amateur kernel hacker in a previous job, I knew that even patch version changes (the third version number) in the kernel can break compilation of custom kernel modules. So, I tried to find a Linux distro that uses the earliest possible patch version of the 2.4 kernel, and still runs well on my workstation.
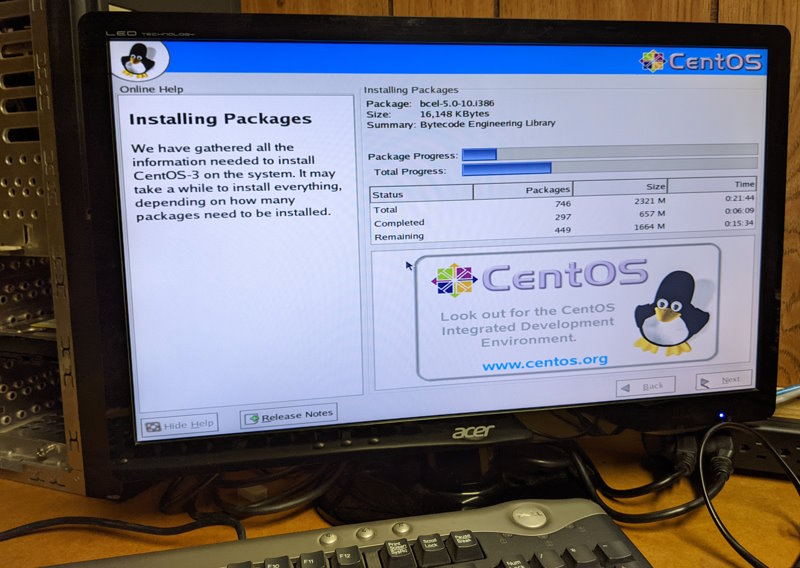
CentOS 3.5 to the rescue! I was able to find ISO installation media that I used to install CentOS 3.5 flawlessly onto my recovery workstation. It uses kernel version 2.4.21, which still turned out to be “too new” for compiling ftape successfully. I got a number of compilation errors, but thankfully they were all errors that were comprehensible and easy to remedy by an amateur. After just a few hacky modifications, I got the driver to compile into a loadable module!
And would you look at that – it’s able to communicate successfully with all of my floppy tape drives, as well as my parallel port Ditto 2GB drive!

Here’s my repository on GitHub that has the source code for the ftape driver, with my modifications for getting it to build in CentOS 3.5.
In other news, I found and restored an old ThinkPad X131e, which came to me as a Chromebook, i.e. with ChromeOS installed. In order to remove ChromeOS and install a regular Linux distro, I had to overwrite it with custom firmware that allows installing other operating systems. And in order to overwrite the firmware, I had to disassemble it and flip a physical write-protect switch that allows the firmware to be written. Why do they do this?! Anyway, with the latest version of the lightweight Xubuntu installed, this tiny thing works beautifully, and can now have a second life.