Suppose you open Android Studio and create a new project from a template, say, a blank Activity with a button. Then build the project, and look at the APK file that is produced. You’ll notice that the APK is over 3 MB in size. These days we don’t bat an eye at these kinds of numbers, and indeed this size is pretty modest in the grand scheme of today’s software ecosystem. However, objectively speaking, 3 MB is a lot! Let’s take a deep dive into what these 3 MB actually consist of, and see how much we can reduce that size while maintaining the same functionality.
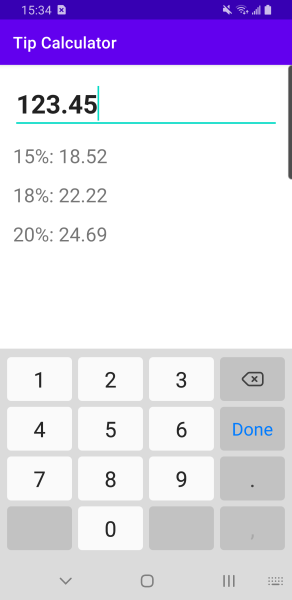
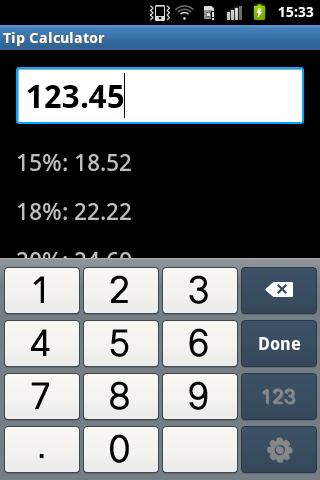
The app I’ve built for this exercise is slightly more complex than “hello world”; it’s an app that could actually be minimally useful: a simple tip calculator.
It’s literally a single input field (an EditText component) where the user enters a number, followed by a few lines of text that tell the user different percentages of that number — 15%, 18%, and 20%, which are the most common tipping percentages in the U.S.
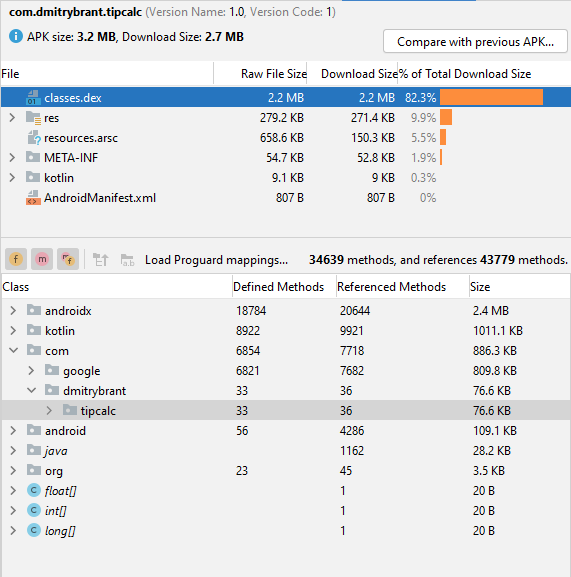
Once again, with the default project settings generated by Android Studio, this app comes out to about 3.2 MB when it’s built. Let’s examine the generated APK file and see what’s taking up all that space:
Right away we can see that the heaviest dependency by far is the AndroidX library, followed by the Kotlin standard library and the Material library (under the com.google package). In fact the code that actually belongs to our package (com.dmitrybrant.tipcalc) is a mere 76 KB, dwarfed by the library dependencies that it’s referencing.
To be fair it’s possible to reduce the size of the APK by a good amount by using the minifyEnabled directive, which is not enabled by default. In fact it would probably optimize away most of the “kotlin” dependency and much of the “androidx” dependency. However, even with minifyEnabled our APK size would still be on the order of megabytes. For the purpose of this exercise I left minifyEnabled off, so that we can see exactly which packages are contributing to the code sizes in our APK.
In any case, let’s start whittling away at this extra weight, and see how lean we can get.
The Kotlin tax
As we can see, merely using Kotlin in our app causes the Kotlin standard library to get bundled into the APK. If we don’t want this library to get bundled, we must no longer use Kotlin. (Although I’ll repeat that if we use minifyEnabled, then Kotlin would pretty much be optimized away, so this is more of an observation than a “tax.”)
After converting the code to plain Java and rebuilding the app, our APK is now 2.7 MB:
That’s a little better! But now can we remove the bulkiest dependency, namely the androidx library?
The AndroidX tax
AndroidX is a fabulous library that ensures your app will run consistently on a huge range of different devices (but not all of them!) and different versions of the Android OS. It makes perfect sense that AndroidX is used by default for new projects, and I’m not saying that you should reject it when building your next app. Buuuut… could we actually get away with not using it? How would our app look and run without it? And would our app still run on the same range of devices?
Getting rid of AndroidX means that our app will rely solely on the SDK libraries that are part of the operating system on the user’s device itself. To get rid of AndroidX in our project, we need to do the following:
- Our Activity can no longer inherit from
AppCompatActivity, and will now simply inherit from the standard Activity class from the SDK. - We can no longer use fancy things like
ConstraintLayout, and will be limited to using basic components like LinearLayout. - Our theme definitions can no longer inherit from predefined Material themes. We will need to apply any color and style overrides ourselves.
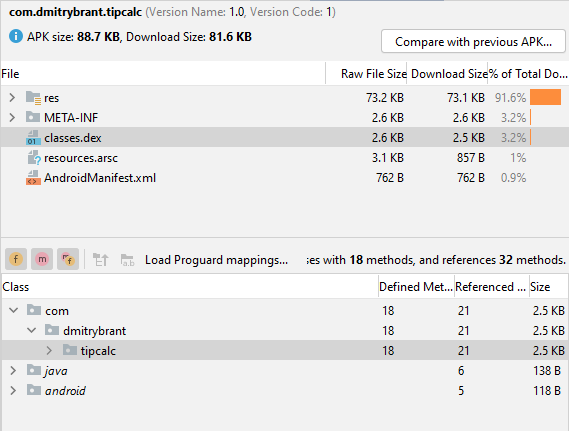
After these modifications are all done, here’s what our APK looks like:
That’s right, you’re not dreaming, the app is now 88 KB. That’s kilobytes! Now we’re getting somewhere. And if we look closely at those numbers, we see that the bulk of the size is now taken up by the resources that are bundled in the app. What are those resources, you ask?
Launcher icons
By default Android Studio generates a launcher icon for our app that takes several forms: a mipmap resource, which is a series of PNG files at different scales, which will be chosen by the launcher to match the pixel density and resolution of the device, and also a vector resource that will be used instead of the mipmap on newer devices (Android 8 and higher).
This is all very useful stuff if you need your launcher icon to appear pixel-perfect across all devices. But since our goal is minimalism, we can dispense with all of these things, and instead use just a single PNG file as our launcher icon. I created a 32×32 icon and saved it as a 4-bit PNG file, making it take up a total of 236 bytes. It doesn’t look perfect, but it gets the point across:
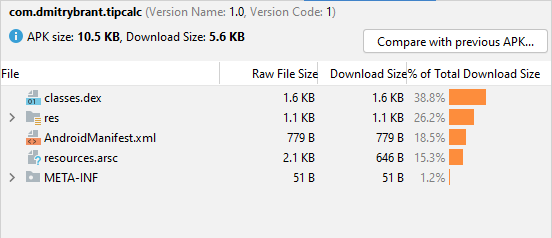
So, after getting rid of all that extraneous baggage, how are we looking now?
We’ve arrived at 10.5 KB! This is more like it. It may be possible to squeeze it down even further, but that would necessitate doing even more hacky and inconvenient things, such as removing all XML resources and creating layouts programmatically in our code. While I’m going for minimalism, I do still want the app to be straightforward to develop further, so I’m happy to make this a good stopping point.
This is definitely closer to the size that I would “expect” a tip calculator app for a mobile device to be. Speaking of mobile devices, which devices will this app be able to run on?
Compatibility
By default Android Studio sets our minimum SDK to 21, making our app compatible with Lollipop and above. There are plenty of good reasons to set your minimum SDK to 21, but now that we’ve removed our dependency on AndroidX, as well as our dependency on vector graphics, there’s nothing stopping us from reducing our minimum SDK even lower. How much lower? How about… 1? That’s right, we can set our minimum SDK version to 1. This would make our app compatible with literally every Android device ever made.
I don’t own any devices that actually run Android 1.0, but here is my Tip Calculator app running on the oldest device I own, a Samsung Galaxy Ace from 2011, running Android 2.3 (API 9):
And here is the same app running on my current personal phone in 2021, a Google Pixel 3 XL running Android 11 (API 30):
Takeaways
Aside from being an interesting random exercise, there’s a point I hope to convey here:
As time goes by, software seems to be getting more and more bloated. I believe this might be because developers aren’t always cognizant of the cost of the dependencies they’re using in their projects, whether it’s third-party libraries that provide some kind of convenience over standard functionality, or even the standard libraries of their chosen programming environment that the developer has gotten used to relying upon.
As with anything in life, there should be a balance here — a balance between convenience offered by libraries that might add bloat, and lower-level optimization and active reduction of bloat. However, it feels like this balance is currently not in a healthy place. The overwhelming emphasis seems to be on convenience and abstraction ad infinitum, and virtually no emphasis on stepping back and taking account of the costs that these conveniences incur.
Android is far from the worst offender in the world of bloat, and even though a 3 MB binary may be totally acceptable, it doesn’t have to be that way. Even though bulky standard libraries should be used in the majority of cases, they don’t need to be used all the time, and there may even be cases where the app would benefit from not using them. If only developers would maintain a better sense of how their dependencies are impacting the size of their apps, or indeed what dependencies they’re even using in the first place, we can begin to restore the balance of bloat in our lives.