I started programming seriously in the late 1990s, when the concept of “visual” IDEs was really starting to take shape. In one of my first jobs I was fortunate enough to work with Borland Delphi, as well as Borland C++Builder, creating desktop applications for Windows 95. At that time I did not yet appreciate how ahead of their time these tools really were, but boy oh boy, it’s a striking contrast with the IDEs that we use today.
Take a look: I double-click the icon to launch Delphi, and it launches in a fraction of a second:
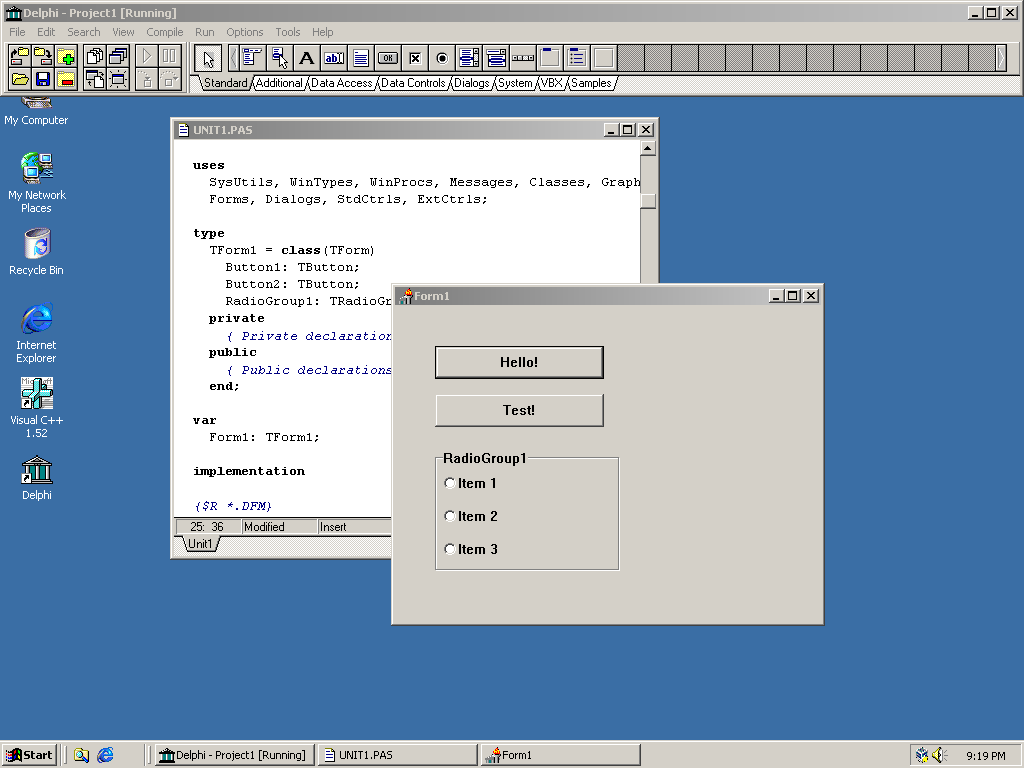
But it also does something else: it automatically starts a new project, and takes me directly to the workflow of designing my window (or “Form” in Borland terms), and writing my code that will handle events that come from the components in the window. At any time I can click the “Run” button, which will compile and run my program (again, in a fraction of a second).
Think about this for a bit. The entire workflow, from zero to building a working Windows application, is literally less than a second, and literally two clicks away. In today’s world, in the year 2020, this is unheard of. Show me a development environment today that can boast this level of friendliness and efficiency!
The world of software seems to be regressing: our hardware has been getting faster and faster, and our storage capacity larger and larger, and yet our software has been getting… slower. Think about it another way: if we suppose that our hardware has gotten faster by two orders of magnitude over the last 20 years, and we observe that our software is noticeably slower than it was 20 years ago, then our software has gotten slower by two orders of magnitude! Is this… acceptable? What on earth is going on?
Laziness
Engineers like to reuse and build upon existing solutions, and I totally understand the impulse to take an existing tool and repurpose it in a clever way, making it do something for which it wasn’t originally intended. But what we often fail to take into account is the cost of repurposing existing tools, and all the baggage, in terms of performance and size, that they bring along and force us to inherit.
Case in point: suppose that the only language you know is JavaScript, and suppose that you wanted to start building desktop applications, but didn’t want to learn the languages and tools normally associated with desktop development, e.g. C++, C#, etc. What can you do? Well, one option would be to build a compiler from scratch, which would actually compile JavaScript into native machine code. But that would be hard. How about a simpler solution: take a full-blown web browser, and literally bundle it as the engine that will run your desktop app, with the logic of your app being in JavaScript, and the “window” of your app becoming a web page that is run by the bundled browser! This is, of course, the idea behind Electron, an alarmingly popular framework for building desktop apps today.
But what about the cost of using Electron? What is the cost of bundling all of Chromium just to make your crappy desktop app appear on the screen? Just to take an example, let’s look at an app called Etcher, which is a tool for writing disk images onto a USB drive. (Etcher is actually recommended by the Raspberry Pi documentation for copying the operating system onto an SD card.)
We know how large these types of tools are “supposed” to be (i.e. tools that write disk images to USB drives), because there are other tools that do the same thing, namely Rufus and Universal USB Installer, both of which are less than 2 MB in size, and ship as a single executable with no dependencies. And how large is Etcher by comparison? Well, the downloadable installer is 130 MB, and the final install folder weighs in at… 250 MB. There’s your two-orders-of-magnitude regression! Looking inside the install folder of Etcher is just gut-wrenching:
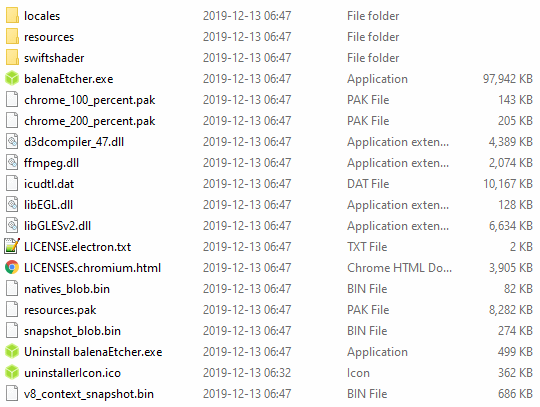
Why is there a DLL for both OpenGL and DirectX in there? Apparently we need a GPU to render a simple window for our app. The “balenaEtcher” executable is nearly 100 MB itself. But do you see that “resources” folder? That’s another 110 MB! And do you see the “locales” folder? You might think that those are different language translations of the text used in the app. Nope — it’s different language translations of Chromium. None of it is used by the app itself. And it’s another 5 MB. And of course when Etcher is running it uses 250+ MB of RAM, and a nonzero amount of CPU time while idle. What is it doing?!
As engineers, this is the kind of thing that should make our skin crawl. So why are we letting this happen? Why are we letting software get bloated beyond all limits and rationalize it by assuming that our hardware will make up for the deficiencies of our software?
The web
The bloat that has been permeating the modern web is another story entirely. At the time of this writing, the New York Times website loads nearly 10 MB of data on a fresh load, spread over 110 requests. This is quite typical of today’s news websites, to the point where we don’t really bat an eye at these numbers, when in fact we should be appalled. If you look at the “source” of these web pages, it’s tiny bits of actual content buried in a sea of <script> tags that are doing… something? Fuck if I know.
The bloat seen on the web, by the way, is being driven by more nefarious forces than sheer laziness. In addition to building a website using your favorite unnecessary “framework” that you can choose willy-nilly (which varies with every web developer you ask, and then has to be hosted on a separate CDN because your web server can’t handle the load), you also have to integrate analytics packages into your website, as requested by your marketing department, and another analytics package requested by your user research team, and another analytics package requested by your design team, etc. If one of the analytics tools goes out of fashion, leave the old code in! Who knows, we might need to switch back to it someday. It doesn’t seem to be impacting load speeds… much… on my latest MacBook Pro. The users won’t even notice.
And of course, ads. Ads everywhere. Ads that are basically free to load whatever arbitrary code they like, and are totally out of the control of the developer. Oh, you say the users are starting to use ad blockers? Let’s add more code that detects ad blockers and forces users to disable them!
The web, in other words, has become a dumpster fire. It’s a dumpster fire of epic proportions, and it’s not getting better.
What to do?
What we need is for more engineers to start looking at the bigger picture, start thinking about the long term, and not be blinded by the novelty of the latest contraption without understanding its costs. Hear me out for a second:
- Not everything needs to be a “framework” or “library.” Not everything needs to be abstracted for all possible use cases you can dream of. If you need code to do something specific, sometimes it’s OK to borrow and paste just the code you need from another source, or god forbid, write the code yourself, rather than depending on a new framework. Yes, you can technically use a car compactor to crack a walnut, but a traditional nutcracker will do just fine.
- Something that is clever isn’t necessarily scalable or sustainable. I already gave the example of Electron above, but another good example is node.js, whose package management system is a minor dumpster fire of its own, and whose dependency cache is the butt of actual jokes.
- Sometimes software needs to be built from scratch, instead of built on top of libraries and frameworks that are already bloated and rotting. Building something from the ground up shouldn’t be intimidating to you, because you’re an engineer, capable of great deeds.
- Of course, something that is new and shiny isn’t necessarily better, either. In fact, “new” things are often created by fresh and eager engineers who might not have the experience of developing a product that stands the test of time. Treat such things with a healthy bit of skepticism, and hold them to the same high standards as we hold mature products.
- Start calling out software that is bad, and don’t use it until it’s better. As an engineer you can tell when your fellow engineers can do a better job, so why not encourage them to do better?
- Learn to say No! When the newest JavaScript framework starts making its rounds, or when the latest “cross-platform” app development framework is unveiled, or when everyone starts talking about microservices, it’s OK to say “No!” “No, thank you!” “Not until we understand how this will be beneficial to us five years from now.” “Not until we understand the costs, in terms of space, performance, and sanity, of adopting this new thing.”
I suppose that with this rant I’m adding my voice to a growing number of voices that have similarly identified the problem and laid it out in even greater detail and eloquence than I have. I wish that more developers would write rants like this. I wish that this was required training at universities. I have a sinking feeling, however, that these rants are falling on deaf ears, which is why I’ll add one more suggestion that we, as engineers, can do to raise awareness of the issue:
Educate regular users about how great software can be. Tell your parents, your friends, your classmates, that a web page shouldn’t actually need ten seconds to load fully. Or that they shouldn’t need to purchase a new generation of laptop every two years, just to keep up with how huge and slow the software is becoming. Or that the software they install could be one tenth of its size, freeing up that much more space for their photos or documents, for example. That way, regular users can be as fed up as we are about the current state of software, and finally start demanding us to do better.


